Информатизация и информационная безопасность правоохранительных органов: XI Международная научная конференция. Сборник трудов – Москва, 2003.
При компьютерной обработке документов в информационно-поисковых и аналитических системах возникает задача выделения в тексте сложных элементов и специальных конструкций, отличающихся особого вида написанием, – наименований юридических лиц, товаров, адресов, номеров и т.п. В большинстве случаев правила написания подобных объектов выходят за рамки общих правил грамматики русского языка, являются неочевидными и трудно формализуемыми.
Для решения данной задачи компанией Гарант-Парк-Интернет (http://www.rco.ru) разработан программный компонент RCO Pattern Extractor, который поставляется в виде инструментария разработчика. RCO Pattern Extractor предназначен для анализа текста и распознавания в нем различных объектов в соответствии с образцами, заданными на формальном языке. Прототипом компонента послужила зарубежная система JAPE [1], грамматика языка которой была взята за основу и расширена рядом средств для работы с русским языком. Общие принципы построения систем подобного класса и примеры их использования описаны в [2-3].
Мощный язык описания образцов объектов позволяет оперировать как формальными особенностями написания слов, используя, в частности, язык регулярных выражений, так и всеми их грамматическими атрибутами – частью речи, родом, числом, падежом и т.д.
Образцы сложных объектов могут строиться иерархически, включая образцы более простых, что позволяет постепенно наращивать мощность системы целевых описаний. Грамматика языка описания образцов обеспечивает как бесконтекстное, так и контекстно-зависимое распознавание объектов.
В этой статье описываются принципы работы компонента RCO Pattern Extractor, который состоит из трех основных подсистем:
- Модуль предобработки текста – производит фрагментацию текста на предложения и лексемы с получением формальных и грамматических атрибутов лексем;
- Словарный модуль – производит сравнение цепочек лексем с образцами, заданными в словарях, и выделяет первичные объекты, присваивая им заданные атрибуты;
- Модуль выделения объектов – производит сравнение цепочек лексем и объектов с образцами, заданными правилами на формальном языке, и выделяет соответствующие образцам объекты, присваивая им любые заданные атрибуты.
1. Модуль предобработки текста
В первую очередь модуль производит фрагментацию текста на предложения и лексемы на основе знаков препинания и тегов HTML, если таковые присутствуют в тексте.
После фрагментации текста модуль производит анализ грамматических характеристик лексем и особенностей их написания. С этой целью в состав компонента входит морфологический анализатор, который обеспечивает обработку как известных, так и неизвестных слов русского языка.
На выходе модуля текст преобразуется в последовательность отдельных предложений, каждое из которых представляет собой цепочку первичных описаний лексем – элементарных объектов, подлежащих последующему анализу. Описание лексемы содержит набор предопределенных атрибутов (всего более 20-ти), например:
- Token.Text – строка лексемы;
- Token.Type – тип лексемы (известное/неизвестное слово русского языка, латинское слово, специальная конструкция);
- множество грамматических характеристик – Morph.SpeechPart (часть речи), Morph.Case (падеж), Morph.Gender (род), Morph.Number (число) и т.п.
Для удобства атрибуты объектов разбиваются на группы с близкой семантикой. Две предопределенные группы Morph и Token содержат множества атрибутов, описывающих грамматические и общие характеристики объектов. Пользователь может вводить свои собственные атрибуты.
Дальнейшее выделение объектов производится по каждому из предложений в отдельности, в ходе чего происходит сравнение атрибутов с заданными значениями и присваивание выделенным объектам новых атрибутов.
2. Выделение объектов
Прежде чем перейти к описанию двух следующих модулей, рассмотрим общие принципы, в соответствии с которыми производится выделение объектов.
Распознавание нового объекта происходит в результате сравнения с заданным образцом некоторой цепочки, которая состоит из описаний других выделенных объектов или просто лексем. Исходной цепочкой для анализа является последовательность лексем, полученных с выхода модуля предобработки.
Распознавание осуществляется в ходе последовательного движения слева направо по цепочке описаний, соответствующей предложению. При этом на каждом шаге все подцепочки, находящиеся справа от текущего элемента цепочки, сравниваются с образцами объектов на предмет совпадения. В результате того, что фрагменты цепочек, соответствующих распознаваемым объектам, могут перекрываться, операция выделения всех непересекающихся объектов является в принципе неоднозначной.
Ввиду наличия множества альтернатив при выделении объектов, для окончательного принятия решения необходимо работать не с отдельной цепочкой, а с целым графом описаний объектов. При распознавании каждого объекта в соответствии с образцом происходит его выделение и формируется описание нового объекта с заданными атрибутами, которое добавляется в граф описаний в качестве альтернативной цепочки.
Выделение может происходить в несколько фаз, когда на каждой последующей фазе выделяются все более сложные объекты, включающие в себя объекты, выделенные на предыдущих фазах. Причем первая фаза реализуется в словарном модуле, а все последующие – в модуле выделения объектов. В общем случае, правила каждой фазы работают не на цепочке, а на целом графе описаний объектов, являющемся результатом работы всех предыдущих фаз обработки.
Пример графа описаний приведен на рисунке 1.
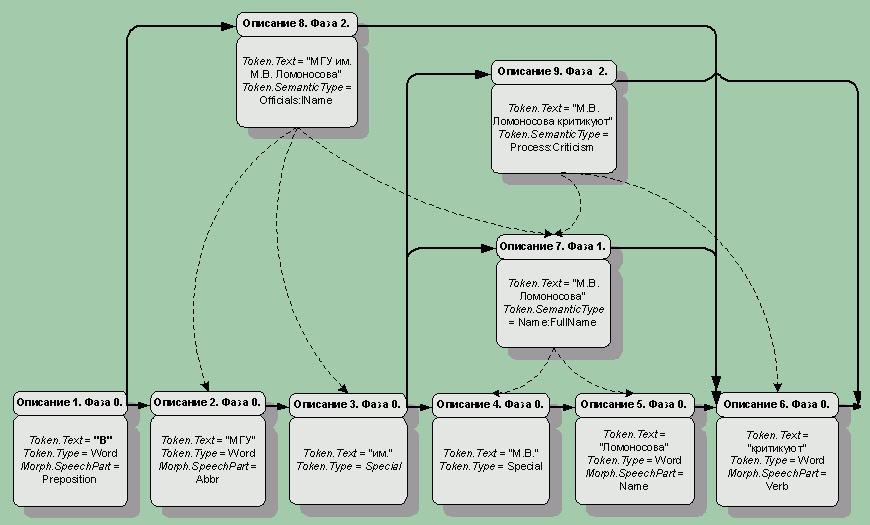
Здесь исходная цепочка описаний лексем с номерами 1-6 соответствует предложению “В МГУ им. М.В. Ломоносова критикуют…” и была получена с выхода предобработчика текста (фаза 0).
На фазе 1 цепочка описаний 4, 5 может быть выделена в объект “М.В. Ломоносова” с описанием 7 (содержит новый атрибут SemanticType = Name:FullName), что добавляет новую цепочку в граф.
На фазе 2 цепочка описаний 2, 3, 7 может быть выделена в объект “МГУ им. М.В. Ломоносова” с описанием 8 (содержит новый атрибут SemanticType = Officials:Name), что добавляет еще одну цепочку в граф.
На этой же фазе цепочка описаний 7 и 6 может быть выделена в объект “М.В. Ломоносова критикуют” с описанием 9 (содержит новый атрибут SemanticType = Process:Criticism).
Как видно, любой из путей в этом ориентированном графе {1,2,3,4,5,6}, {1,2,3,7,6}, {1,2,3,9}, {1,8,6} представляет корректное (с точки зрения использованных правил) покрытие предложения выделенными непересекающимися объектами.
Очевидно, что наиболее логичной интерпретацией данного графа является выбор в нем кратчайшего пути {1,8,6}, ведущего от начала предложения к его концу – цепочки из трех объектов.
Таким образом, окончательно будет принято решение о выделении целевого объекта “МГУ им. М.В. Ломоносова”, а цепочка “М.В. Ломоносова критикуют”, распознанная в соответствии с образцом для критики физического лица, выделяться в объект не будет.
Грамматика формального языка, используемого в RCO Pattern Extractor, позволяет задавать несколько видов семантики применения правил для каждой фазы обработки, определяя, будут ли анализироваться все пути в графе описаний или только кратчайший путь.
3. Словарный модуль
Модуль производит сравнение цепочек лексем, заданных своими описаниями, с цепочками лексем из заданных словарей – словарными образцами. Каждая распознанная цепочка выделяется в новый объект-лексему, который получает свое описание, используемое на следующем этапе обработки. Результатом работы модуля является граф описаний.
Прежде всего в словарном модуле выделяются и описываются различные ключевые слова и словосочетания, которые входят в состав сложных целевых объектов и необходимы для их распознавания на следующем этапе – например, слова “фирма”, “ООО”, “открытое акционерное общество” и другие необходимы для распознавания сложных названий организаций. Однако здесь же могут выделяться конкретные целевые объекты, например “Московский государственный университет им. М.В. Ломоносова”, “МГУ”.
Словарные образцы объектов позволяют задавать три способа распознавания: сопоставление всех лексем в цепочке с учетом морфологии (во всех грамматических формах), сопоставление всех лексем в заданных грамматических формах независимо от регистра, точное сопоставление цепочки “как есть”.
В результирующее описание выделенного объекта входят:
- Текст строки, соответствующей цепочке – задается в качестве синонима в словаре или соответствует исходному тексту цепочки;
- Грамматические атрибуты – наследуются от заданного слова в цепочке либо задаются явно в словаре;
- Семантический тип – задается в словаре;
- Ряд прочих атрибутов.
Пример 1. Словарь частей наименований организаций
Officials:KeyWord // Значение атрибута SemanticType, присваиваемое объектам
ООО SYN // Распознавать, “как есть”
Открытое акционерное MAIN общество MSYN ООО
В последнем случае распознавание производится с учетом морфологии во всех грамматических формах, в выделенном объекте все грамматические атрибуты наследуются от слова “общество”, перед которым указано ключевое слово MAIN, а исходная строка заменяется синонимом “ООО”.
4. Модуль выделения объектов
Модуль осуществляет распознавание и выделение объектов в соответствии с правилами, заданными на формальном языке.
Грамматика языка поддерживает задание последовательности фаз выделения объектов, а каждая фаза состоит из набора правил. Фазы выполняются последовательно, и каждая фаза может обрабатывать цепочки описаний всех объектов, выделенных в результате работы предыдущих фаз.
Правила состоят из левой и правой части и имеют вид “образец -> описание”. Выражение в левой части правила задает образец, в соответствии с которым происходит распознавание объекта. Выражение в правой части задает атрибуты, которые получает описание объекта в случае его выделения.
Образец представляет собой логическое выражение на формальном языке, которое задает условия на значения атрибутов в цепочке описаний, соответствующей распознаваемому объекту. Для удобства работы образец может быть записан посредством использования макросов, описывающих отдельные части логического выражения.
В левой части правила позволяется определять метки для выбранных описаний из цепочки с целью их последующего использования в правой части правила, например, для наследования грамматических атрибутов. Метки также позволяют объединять в выделяемый объект не все объекты цепочки, распознанной в соответствии с образцом, а лишь заданное подмножество, что позволяет осуществлять контекстно-зависимое распознавание объектов.
Пример 2. Образец для распознавания косвенной речи
Macro: SPEECH_VERB
(
({Token.Text =| “говорить”}) |
({Token.Text =| “сказать”}) |
((({Token.Text =| “отмечать”}) |
({Token.Text =| “отметить”}))
{Token.Text == “,”} {Token.Text =^ “что”})
)
В приведенном примере описан образец для распознавания в тексте некоторых показателей косвенной речи. Макрос SPEECH_VERB описывает логическое выражение – образец для распознавания цепочек текста “говорить”, “сказать”, “отмечать, что” и “отметить, что”. Оператор “|” (логическое ИЛИ) используется для задания возможных альтернатив. При этом распознавание всех глаголов производится с учетом морфологии (во всех грамматических формах), распознавание запятой – как есть, а распознавание слова “что” – в заданной форме, но без учета регистра, для чего использованы соответствующие операторы сравнения “=|”, “==” и “=^”.
Пример 3. Правило для выделения “спичмейкеров”
Rule: SpeechMakerRule
(
({Morph.IsAnimate==”Animate”}):getmorph |
({Token.SemanticType==”Name:FullName”}):getmorph
) :speech_maker SPEECH_VERB
–> :speech_maker.Token = { SemanticType = “Speech:Maker”, Text = :speech_maker.Token.Text },
:speech_maker.Morph = { :getmorph.Morph }
Правило SpeechMakerRule позволяет выделить всех “производителей” косвенной речи – так называемых “спичмейкеров”, обозначенных в тексте одушевленными существительными или именами собственными. При этом предполагается, что имена собственные (которые могут состоять из нескольких лексем) выделяются другим правилом на предыдущей фазе обработки, и соответствующие объекты получают атрибуты Token.SemanticType=”Name:FullName”. Для распознавания косвенной речи, которая должна следовать в тексте за упоминанием “спичмейкера”, используется макрос SPEECH_VERB, определенный в примере 1.
Данный пример иллюстрирует контекстно-зависимое выделение – в качестве объекта выделяется не вся цепочка, распознанная в соответствии с образцом, а лишь ее часть, заданная меткой :speech_maker.
В выделенном объекте атрибуту Token.Text присваивается значение атрибута Token.Text объекта, распознанного под меткой :speech_maker, а всем атрибутам группы Morph присваиваются значения из описания объекта с меткой :getmorph.
Символы “*”, “+” и “?” представляют собой операторы, которые могут применяться к любой части логического выражения в левой части правила, заключенной в круглые скобки, и позволяют эффективно обрабатывать повторяющиеся конструкции любой длины. Часть выражения, за которой следует символ “?”, распознается ноль или один раз. Часть выражения, за которой следует символ “*”, распознается ноль или более раз. Часть выражения, за которой следует символ “+”, распознается один или более раз.
Например, выражение ({!Token.Text == “” })* позволяет описать повторение любой лексемы в предложении произвольное число раз или вообще ее отсутствие. Оператор “!” обозначает отрицание условия.
Следующее выражение позволяет описать образец для распознавания прямой речи, когда после двоеточия в кавычках может следовать любое количество слов, но не менее одного: {Token.Text==”:”} {Token.Text==”\””} ({!Token.Text == “\”” })+ {Token.Text== “\””}
Пример 4. Правило для выделения интервалов дат
Macro: PREP // предлог
(
({Morph.SpeechPart==”Preposition”})
)
Macro: REPЕАТ // лексемы, задающие перечисление
(
({Token.Text == “,”}) |
({Token.Text =^ “и”}) |
({Token.Text =^ “или”}) |
({Token.Text == “-“})
)
Rule: DateRule
( (PREP)? SINGLE_DATE (REPЕАТ (PREP)? SINGLE_DATE))* ) :date_row
–> :date_row.Token = { Type = “Special”, SemanticType = “Date:DateRow” }
Данный пример иллюстрирует выделение интервалов дат наподобие “Дата1, Дата2 или Дата3”, “Дата1 и с Дата2 по Дата3”, “Дата1 – Дата2, Дата1 – Дата4”, когда перед каждой датой может стоять предлог, а несколько дат может следовать друг за другом. При этом предполагается, что образцы отдельных дат описаны макросом SINGLE_DATE, который в примере не приводится.
При сравнении строковых значений атрибутов та строка, с которой производится сравнение, может быть задана шаблоном, описанным на языке регулярных выражений.
Регулярное выражение представляет собой одну или более ветвей, разделенных символом “|”. Оно сопоставляется в случае, если сопоставляется одна из его ветвей. Ветвь состоит из нуля или более частей, следующих друг за другом и сопоставляемых последовательно одна за другой. За любой частью ветви могут следовать операторы “*”, “+” и “?” которые определяют количество допустимых сопоставлений данной ветви (ноль или более раз, один или более раз, ноль или один раз). Часть ветви представляет регулярное выражение в круглых скобках, диапазон (см. далее), “.” (сопоставляется с любым символом), “\” за которым следует отдельный символ или просто отдельный символ (сопоставляется с этим символом).
Диапазон задается последовательностью символов в квадратных скобках “[]”. Пара символов, разделенных знаком “–”, означает сопоставление с любым символом из заданного диапазона, а отдельный символ означает сопоставление с ним самим. Так, “[0-9]” означает любую цифру, “[А-ЯA-Z]” – любую заглавную букву русского или латинского алфавита, “[АаЯяЫы]” – любую букву из перечисленных в наборе.
Например, для распознавания наименований организаций наподобие “Миноборонпром” или “АВТОПРОМ” и всех их склоняемых форм можно использовать следующее сравнение атрибута с использованием регулярного выражения: Token.Text =~ “[А-Я].+[Пп][Рр][Оо][Мм].*”
Следующий пример иллюстрирует распознавание всех дат 19-го и 20-го столетий, записанных в формате “день.месяц.год”. Регулярное выражение содержит несколько альтернативных ветвей: Token.Text =~ “([1-9]|[0-2][1-9]|3[0-1])\.([1-9]|0[1-9]|1[0-2])\.(19[0-9][0-9]|20[0-9][0-9]|[0-9][0-9])”.
Заключение
Компонент RCO Pattern Extractor уже используется в составе других модулей, разработанных компанией “Гарант-Парк-Интернет” и предназначенных для автоматического анализа текста. Развитые средства для работы с грамматическими атрибутами объектов (в частности, их наследование), поддерживаемые грамматикой формального языка, позволяют естественным образом включить компонент в системы, использующие алгоритмы синтаксического разбора русского текста.
В комплект поставки RCO Pattern Extractor входит стандартный набор образцов для выделения нескольких классов объектов: наименований физических и юридических лиц, дат, адресов, составных географических названий и ряда других объектов. Пользователю предоставляются возможности настройки стандартных образцов и введения своих собственных, описывающих интересующие объекты.
Для настройки образцов объектов можно воспользоваться приложением RCO Pattern Extractor Viewer с графическим интерфейсом, которое позволяет просмотреть результаты анализа текста с использованием заданных образцов и получить сообщения об ошибках, если таковые имеются.
С подробной информацией об описанном компоненте можно познакомиться на сайте http://www.rco.ru.
Литература
1. H. Cunningham and D. Maynard and V. Tablan. JAPE: a Java Annotation Patterns Engine (Second Edition). Technical report CS–00–10, University of Sheffield, Department of Computer Science, 2000.http://gate.ac.uk/gate/doc/papers.html
2. Hobbs, Appelt, Bear, Israel, Kameyama, Stickel and Tyson, FASTUS: A Cascaded Finite-State Transducer for Extracting Information from Natural-Language Text, in Roche and Schabes, eds., Finite State Devices for Natural Language Processing, MIT Press, Cambridge MA, 1996.http://www.ai.sri.com/~appelt/fastus-schabes.html
3. Проект GATE (General Architecture for Text Engineering)http://www.gate.ac.uk/